1. K의 시대
유튜브의 세계는 냉혹하다. 사람의 관심을 받지 못한 컨텐츠들은 유저들에게 외면받는다. 이런 유튜브 세상에서 자신의 영역을 확고히하고 있는 유튜브 컨텐츠가 있다. 이들은 속된말로 "국뽕" 컨텐츠라 한다. 이 컨텐츠들은 흔히 대부분 한국의 좋은 점을 극대화해서 과장하거나 다른 나라들과 한국을 비교하며 다른 나라를 깎아내리는 내용을 담고 있다. 이런 유튜브 영상들은 호불호가 많이 갈려 소비하지 않는 사람들도 많은 편이지만, 상당수의 구독자를 확보하고 몇십만 이상의 조회수를 꾸준히 뽑아내는 "국뽕" 유튜버도 적지 않다.
이들의 영상에서 주목하지 않을 수 없는 특징이 하나 있다. 바로 특유의 길고 온갖 감탄사, 수식어들을 사용한 제목이다. 이 제목들은 대부분 길다 못해 유튜브 창에서는 ...으로 생략되기 마련이며 그 길다란 제목이 자랑스럽기라도 한 듯이 썸네일에 그 제목을 꽉꽉 채워 사람들의 눈길을 끈다. 보기에 추하다는 의견도 많지만 엄연히 이 길고 눈길을 끄는 제목이 조회수에 많은 기여를 한다는 것은 분명해보인다. 이런 제목의 특징은 여러 유튜버들에 걸쳐 공통적으로 나타나는 편이다. 그렇다면 이 "국뽕" 유튜브의 제목에는 어떤 패턴이 있지 않을까? 그리고 이 패턴을 이용해서 제목을 생성할 수 있는 모델을 만들 수 있지 않을까? 이 질문이 이 프로젝트의 시작이다.
2. 프로젝트 소개
프로젝트의 제목에 "국뽕"이라는 단어를 사용하기엔 어감이 부적절한 느낌이 있으므로, 그들이 주로 사용하는 접두사 K-를 활용하여 이러한 성향의 유튜브 영상들을 K-유튜브로 칭하기로 하자. 이 프로젝트의 목적은 K-유튜브의 제목을 생성할 수 있는 모델을 만드는 것이다. 프로젝트 팀은 나와 현재 프로그래머스 데브코스에 참여하고 있는 두명의 수강자로 이루어졌다. 우리는 프로젝트 기간을 최대 한 달로 잡고 데이터 수집, 전처리, EDA, 모델 생성 등의 task들의 계획을 세웠다.
데이터 수집은 Sellenium을 이용해 직접 유튜브에서 크롤링하기로 정했다. 유튜브의 경우 웹 드라이버를 이용한 크롤링이 쉬운편이다. 과거에도 유튜브에서 크롤링을 진행해본적이 있었는데 유튜버 별로 고유 URL이 있고 영상제목, 조회수, 좋아요 수 등의 정보가 들어있는 태그가 고정되어 있어 크롤링하기 수월했다. 우리는 "K-유튜브"의 경우 주로 올리는 유튜버가 정해져 있고, 그 유튜버는 거의 대부분 그런 성향의 영상만 올린다는 사실을 확인했다. 이런 유튜버들을 이른바 "K-유튜버"라고 정하고 이 유튜버의 목록을 생성한 후, 영상들의 제목을 크롤링한다는 계획을 세웠다. 물론 어떤 유튜버를 "K-유튜버"라고 정하냐는 문제는 객관적인 기준이 없으므로 해결하기 곤란한 문제였지만 팀원끼리 상의하여 만장일치로 동의하면 K-유튜버라고 분류하기로 했다. 이를 통해 주관적인 특성도 반영하면서 나름의 객관성도 가져가는 방식으로 유튜버 리스트를 작성했다. 이 유튜버의 리스트를 셋으로 나눠 각자의 환경에서 크롤링하였고 이 데이터들을 합치는 방식으로 진행했다.
생성 모델은 오픈소스로 공개되어 있는 KoGPT2를 사용하기로 했다. GPT는 transformer를 기반으로 발전한 pre-trained 모델로, 다양한 Task에 적용할 수 있지만 특히나 자연어 생성에도 잘 활용되기로 유명하다. KoGPT2는 오픈소스여서 가져다 쓰기도 쉽고 관련 예제도 쉽게 찾아볼 수 있으며, 대량의 한국어 Corpus를 미리 학습한 상태라 한국어 생성 모델을 만드는데 적합하다는 장점들을 가지고 있기 때문에 KoGPT2를 이번 프로젝트에 사용할 메인 모델로 선정했다.
3. EDA
우리는 크롤링을 통해 유튜브 제목, URL, 좋아요 수, 조회수, 유튜버의 이름, 업로드 날짜. 태그, 구독자 수 데이터를 수집했다. 물론 유튜브 제목을 생성하는 모델을 만들기 위해선 유튜브 영상들의 제목만 있어도 충분하지만 먼저 이 데이터들을 EDA 해보며 K-유튜버들과 그 영상에는 어떤 특성이 있는지 분석해보기로 했다. 각자 크롤링하여 합쳐진 최종 데이터를 이용해 EDA를 진행했고 서로 토론을 하면서 EDA를 통해 볼 수 있는 의미들을 해석해보기로 했다.
3-1. 이들은 언제부터 등장했는가?
일반적인 대중들은 유튜브에 K-유튜버들이 존재한다는 사실은 많이 알고 있지만 이들이 언제부터 등장하기 시작했는지에 대해선 관심이 없는 경우가 많을 것이다. 우리 팀 역시 그랬다. 영상이 각광을 받기 시작한 것은 최근이지만 이들이 예전부터 K-유튜브를 올리고 있었는데 나중에 관심을 받은 것인지 최근부터 영상을 올리기 시작한 것인지는 모르는 일이다. 그러나 EDA를 진행한 결과 이들이 등장한 시기는 매우 명확해보였다.

크롤링한 영상들의 업로드 날짜를 기준으로 각 유튜버들이 언제부터 영상을 올리기 시작했는지를 보기위해 Range Chart를 그려보았다. 그러자 오래전부터 활동해온 영국남자 채널을 제외하고 대부분의 영상들이 2019년부터 활발하게 올라오기 시작했다는 사실을 알 수 있었다. 2019년은 무슨 해인가? 바로 "일본 불매운동"이 한참 유행하고 있을 시기였다. 구글의 검색어 트렌드를 보더라도 일본 불매운동에 대한 관심은 2019년에 급격히 증가한다.
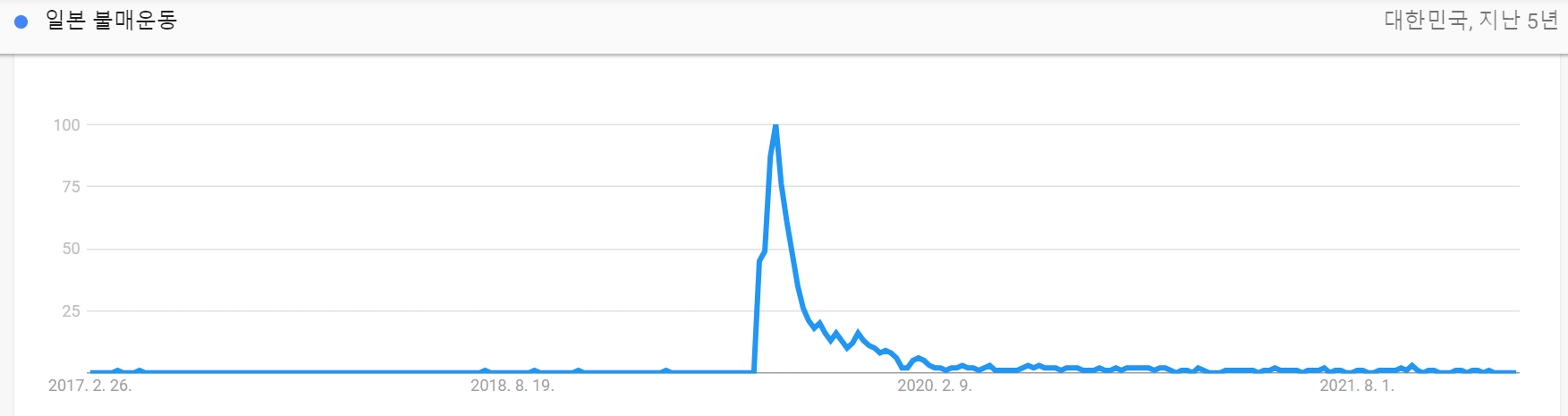
유튜브 영상의 갯수를 직접 세어보더라도 명확한 차이를 보인다. 2018년의 영상의 수는 131개였지만 2019년엔 819개로 약 6배정도 폭발적으로 증가한다. 아래의 히스토그램이 그 사실을 보여준다. 이 EDA를 통해 이들은 한국에 대한 자존심으로 꾸준히 활동하던 유튜버들이 아닌, 어떤 이슈를 이용하여 의도적으로 조회수를 올리기 위해 등장한 유튜버들이라고 추정할 수 있다.

3-2. K-유튜브의 트렌드
K-유튜브가 일본 불매운동을 계기로 시작되었다면 그들은 2022년 현재까지 어떤 영상들을 만들어왔을까? 이들의 영상에도 트렌드가 있을 것이다. 나는 먼저 유튜브 영상들에 달린 해시태그를 통해 이 트렌드를 찾아보고자 했다. 처음엔 연도별로 해시태그들의 갯수를 세면 해당 연도의 영상 트렌드를 볼 수 있지 않을까 생각했지만 그런 방식으로는 트렌드를 찾기가 어려웠다. 모든 연도에서 #일본, #한국, #외국 등, 트렌드와는 관련없는 일반적인 해시태그가 가장 많은 것으로 나왔다. 이런 해시태그로는 이들이 일본을 비롯한 외국 이슈에 관심이 많은 것을 알 수는 있지만 트렌드를 보기는 어렵다. 그래서 나는 해시태그의 갯수에 후처리를 해주어 트렌드를 볼 수 있는 지표를 만들기로 했다.
먼저 각 해시태그의 갯수를 해당연도에 올라온 영상 수로 나누었다. 우리 팀이 수집한 데이터는 연도별로 영상의 수가 다르고 2022년 데이터의 경우에는 현재인 2월까지의 데이터만 수집할 수 있었으니 단순히 해시태그의 수로 비교를 하면 정보가 왜곡될 가능성이 있다고 생각했다. 이 방법은 영상들중에서 해당 해시태그가 쓰인 영상의 비율을 구하는 것과 같다고 볼 수 있다. 나는 이 수치를 '해시태그의 점유율'이라고 하겠다.
그리고 트렌드를 관찰하기 위해서는 모든 연도에 걸쳐 일반적으로 쓰이는 해시태그가 아니라, 전년도에 비해 늘어난 해시태그를 관찰하는게 맞다고 생각했다. 즉 2019년과 2020년에 각각 100번씩 쓰인 해시태그보단, 2019년엔 쓰이지 않다가 2020년에 20번 쓰인 해시태그가 더 트렌드를 관찰하는데에는 중요하다는 것이다. 그래서 나는 전년도의 해시태그 점유율로 다음해의 점유율을 얼마나 높은 비율로 점유율이 증가했는지 관찰하고자 했다. 다만 이 경우 한번도 쓰이지 않은 해시태그는 점유율 역시 0이기 때문에 'devide with zero' 문제가 발생할 수 있다. 따라서 나는 점유율의 0값을 매우 0에 가깝지만 0은 아닌 값으로 바꿔주었다.(ex. 0.0000001)
또한 트렌드를 관찰하기 위한 데이터는 2019년 이후의 데이터만 사용하였다. K-유튜브가 대량 발생하기 시작한 시점이 2019년이고 그 이전의 데이터는 빈약하기 때문에 의미가 없다고 생각했다. 따라서 2019-2022년 기간의 K-유튜브 데이터를 이용해 트렌드를 관찰했다. 아래의 사진은 위에서 구한 점유율의 변화율을 바탕으로 해시태그를 이용해 wordcloud를 그린 것이다.
| 2019-2020 | 2020-2021 | 2021-2022 |
 |
 |
 |
2019-2020년 사이의 트렌드를 보면 #네티즌반응, #외신반응 등의 해시태그들이 눈에 띈다. K-유튜버들이 처음 발생했던 2019년의 경우 대부분이 이슈를 정리해 보여주는 이른바 '이슈 유튜버'의 형태였으나 그 영역에서 특히 외국인들의 반응을 집중하여 다루는 유튜버들이 갈라져나왔다. 이 들의 영상에서 나오는 외국인 반응들은 대부분 한국의 장점을 극찬하는 내용을 담고있다. 그리고 2020년은 코로나-19 바이러스가 전세계적으로 퍼지기 시작한 때 였으므로 #코로나, #진단키트 , #이시국등의 해시태그들이 보인다.
2021년은 '오징어 게임'의 해였다. 넷플릭스 드라마 오징어게임은 전세계 넷플릭스에서 1위를 차지함으로써 K-컨텐츠의 위력에 취하기에 딱 좋은 키워드였다. #오징어게임, #이정재, #한류열풍 등의 해시태그들이 보인다. 또한 영화 #미나리와 여기에 출현하여 큰 상을 수상한 #윤여정, 처음으로 100% 한국 기술로 만들어져 쏘아올려진 로켓 #누리호 해시태그가 눈에 띈다. 해외이슈에 관련해서는 미군이 아프가니스탄에서 후퇴한 후 벌어진 사건들을 다루는 #아프가니스탄, #아프간 등의 해시태그들이 보인다.
2022년은 베이징 동계올림픽에 관한 이슈와 여기서 터진 편파판정 논란으로 해시태그들이 뒤덮혔다. #쇼트트랙, #베이징동계올림픽, #황대헌, #한국대표팀, #범내려온다와 같은 해시태그들이 보인다. 또한 최근 인기를 얻은 넷플릭스 드라마 #지금우리학교는 역시 보인다. 지금우리학교는에 대한 해외반응을 다뤘는지 #지금우리학교는해외반응과 같은 해시태그도 보인다.
해시태그 분석에 이어 유튜브 제목들을 분석했다. K-유튜브의 제목들은 신조어나 '오징어게임'과 같은 사전에 등재되지 않은 고유명사들이 많아 일반적인 형태소 분석기로는 tokenize를 하는 것이 부적절하다고 생각했다. 따라서 오픈소스 자연어처리 라이브러리인 나는 soynlp를 이용했다. soynlp는 사전을 사용한 지도학습 기반이 아닌 비지도학습 기반으로 만들어진 토크나이저를 제공한다. 나는 soynlp의 추출기중 명사를 추출하는 NewsNounExtractor를 사용하여 tokenize를 진행했다. 유튜브 제목들을 tokenize했고, '은', '는', '이', '가', '에서'와 같은stopwords들을 제거했다.
트렌드를 비교하는 방식으로 해시태그의 경우와 동일하게 점유율과 변화율을 구하여 wordcloud를 그렸다. 그려진 결과는 다음과 같다.
| 2019-2020 | 2020-2021 | 2021-2022 |
 |
 |
 |
단어를 통해 진행한 트렌드분석도 해시태그로 진행한 결과와 크게 다르지 않았다. 토크나이저가 완벽하지 않아 명사가 아닌 단어도 섞였고 조사가 분리되지 않은 단어도 있어 보기에 좀 더 어렵긴하지만 대체적으로 2020(코로나, 해외반응) -> 2021(오징어게임, 아프간) -> 2022(베이징올림픽)의 트렌드 변화를 보여준다. 다만 해시태그 분석에선 보이지 않았던 2021년 요소수 대란에 관한 키워드를 새롭게 보여주었다.
3-3 그 외 분석

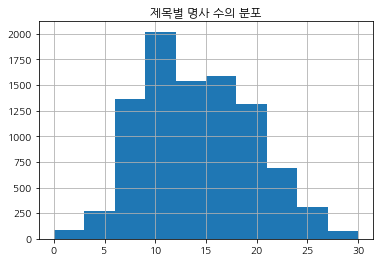

마지막으로 제목과 태그 수에 관한 간단한 분석을 거쳤다. 영상 제목들의 길이는 20자부터 80자까지 범위가 넓은 편이었으며, 명사의 수로 세보면 대부분 10~20개의 명사를 사용했다. 태그의 경우는 3개이상의 태그를 사용한 영상이 가장 많았지만 태그를 사용하지 않은 영상도 많다는 것을 알 수 있었다.
'Project' 카테고리의 다른 글
| [프로젝트]모델의 inference time을 줄이기 위한 발버둥 (0) | 2022.04.19 |
|---|---|
| SRGAN 논문 코드로 구현해보기 (0) | 2022.03.10 |
| KoGPT2를 활용해 K-유튜브 제목을 생성해보자 - 2편 파인튜닝 (0) | 2022.03.06 |