- 주의: 이 포스팅은 제가 읽고 이해한대로 작성하는 논문리뷰이며 학문적인 오류나 오역이 있을 수 있습니다.
논문링크: https://arxiv.org/abs/1809.00219
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
The Super-Resolution Generative Adversarial Network (SRGAN) is a seminal work that is capable of generating realistic textures during single image super-resolution. However, the hallucinated details are often accompanied with unpleasant artifacts. To furth
arxiv.org
참고 코드 링크: https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/esrgan/esrgan.py
GitHub - eriklindernoren/PyTorch-GAN: PyTorch implementations of Generative Adversarial Networks.
PyTorch implementations of Generative Adversarial Networks. - GitHub - eriklindernoren/PyTorch-GAN: PyTorch implementations of Generative Adversarial Networks.
github.com
서론
SRGAN 이전까지 Super-resolution task는 PSNR을 최적화하는 방향으로 이루어졌다. PSNR은 MSE를 기반으로 한, 이미지가 얼마나 손실되었는지 판단하는 지표인데 딥러닝 네트워크를 PSNR 최적화에 초점을 맞춰 설계하면 결과물 이미지가 디테일이 뭉개져서 과하게 부드러워지는(over-smoothed) 현상이 발생하게 된다.
SRGAN은 GAN 네트워크를 Super-resolution task에 활용해서 이 부드러워지는 현상을 해결하려고 했다. 그 결과 시각적으로 만족스러운 결과를 낼 수 있게 되었다. 하지만 SRGAN의 결과는 여전히 실제 HR 이미지와는 거리가 있었다. ESRGAN은 SRGAN을 보완하기 위해 다음과 같은 세 가지 측면에서 모델을 개선했다.
1. 네트워크 구조 개선(RDDB, 배치정규화 제거, Residual scaling, smaller initialization)
2. Discriminator에 상대적인 realistic을 평가하는 Relativistic average GAN(RaGAN) 구조 사용
3. VGG loss를 구할 때, 활성화 함수를 통과하기 전의 값을 사용하기
네트워크 구조

위 그림은 ESRGAN 논문에 실린 SRGAN의 residual block과 ESRGAN의 RRDB 구조를 비교하는 그림이다. SRGAN의 경우는 Residual Block을 여러개 연결하고 residual connection을 사용했다면, RRDB는 Dense Block을 연결하고 residual scaling을 사용했다. Dense Block의 경우 convolution layer와 Leaky ReLU로 이루어진 레이어들 간에 Dense connection을 사용한 블럭이다. Dense connection은 이전 레이어의 output을 현 레이어의 input과 concat해서 같이 레이어를 통과시키는 방법인데, residual connection이 elementwise sum을 사용한다면 Dens connection은 두 텐서를 concat한다는 점이 다르다. 코드를 보면 이해가 더 쉽다.
class DenseResidualBlock(nn.Module):
"""
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
"""
def __init__(self, filters, res_scale=0.2):
super(DenseResidualBlock, self).__init__()
self.res_scale = res_scale
def block(in_features, non_linearity=True):
layers = [nn.Conv2d(in_features, filters, 3, 1, 1, bias=True)]
if non_linearity:
layers += [nn.LeakyReLU()]
return nn.Sequential(*layers)
self.b1 = block(in_features=1 * filters)
self.b2 = block(in_features=2 * filters)
self.b3 = block(in_features=3 * filters)
self.b4 = block(in_features=4 * filters)
self.b5 = block(in_features=5 * filters, non_linearity=False)
self.blocks = [self.b1, self.b2, self.b3, self.b4, self.b5]
def forward(self, x):
inputs = x
for block in self.blocks:
out = block(inputs)
inputs = torch.cat([inputs, out], 1)
return out.mul(self.res_scale) + x위 코드는 Dense Block을 nn.Module을 사용해 구현한 코드인데, forward 부분을 보면 torchc.cat을 통해 input과 output을 concat하고 다음 레이어에 input으로 들어가는 구조를 볼 수 있다. 이런 방식으로 가면 input layer의 채널이 점점 늘어나게 되지만 마지막 레이어의 output의 채널 수는 filters 만큼이 되기 때문에 최종 output의 채널 수는 보존된다.
그리고 return 부분을 보면 residual scaling이 사용된 것을 볼 수 있다. 일반적인 residual connection이라면 out + x를 리턴하겠지만 res_scale 인자를 받아 out에 곱해줌으로써 residual connection을 전부 연결하지 않고 스케일링하여 연결해주었다.
이 Dense Block을 연결해 최종적으로 만들어지는 RRDB Block은 논문의 그림처럼 3개의 Dense Block을 reidual scailing을 사용해 연결했다. 코드는 다음과 같다.
class ResidualInResidualDenseBlock(nn.Module):
def __init__(self, filters, res_scale=0.2):
super(ResidualInResidualDenseBlock, self).__init__()
self.res_scale = res_scale
self.dense_blocks = nn.Sequential(
DenseResidualBlock(filters), DenseResidualBlock(filters), DenseResidualBlock(filters)
)
def forward(self, x):
return self.dense_blocks(x).mul(self.res_scale) + x
class GeneratorRRDB(nn.Module):
def __init__(self, channels, filters=64, num_res_blocks=16, num_upsample=2):
super(GeneratorRRDB, self).__init__()
# First layer
self.conv1 = nn.Conv2d(channels, filters, kernel_size=3, stride=1, padding=1)
# Residual blocks
self.res_blocks = nn.Sequential(*[ResidualInResidualDenseBlock(filters) for _ in range(num_res_blocks)])
# Second conv layer post residual blocks
self.conv2 = nn.Conv2d(filters, filters, kernel_size=3, stride=1, padding=1)
# Upsampling layers
upsample_layers = []
for _ in range(num_upsample):
upsample_layers += [
nn.Conv2d(filters, filters * 4, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(),
nn.PixelShuffle(upscale_factor=2),
]
self.upsampling = nn.Sequential(*upsample_layers)
# Final output block
self.conv3 = nn.Sequential(
nn.Conv2d(filters, filters, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(),
nn.Conv2d(filters, channels, kernel_size=3, stride=1, padding=1),
)
def forward(self, x):
out1 = self.conv1(x)
out = self.res_blocks(out1)
out2 = self.conv2(out)
out = torch.add(out1, out2)
out = self.upsampling(out)
out = self.conv3(out)
return outRRDB 블럭의 코드와 Generator 전체의 코드다. Generator의 코드의 RRDB 블럭 이외의 부분은 SRGAN과 구조가 동일해보인다. Generator 쪽에서는 RRDB를 사용하여 모델을 더 깊게 만들고 학습을 용이하게 만들었다는 점이 가장 큰 변화인 것 같다.
Relativistic Discriminator(RaGAN)
ESRGAN의 Discriminator는 최종 결과물 자체를 통해서만 해당 이미지가 real인지 fake인지 구별하지 않는다. RaGAN의 아이디어를 사용하여 생성된 이미지의 피쳐맵과 진짜 이미지의 피쳐맵의 평균과 차이를 구한 뒤, 그 값이 real인지 fake인지를 구별한다. 논문에 삽입된 수식은 다음과 같다.
이 그림은 일반적인 GAN과 RaGAN의 Discriminator가 어떻게 다른지 보여준다. RaGAN에서 사용하는 평균은 모든 미니배치의 real, fake 이미지 피쳐맵을 합쳐 평균낸 것이다. 이것을 코드로 구현하면 다음과 같다.
criterion_GAN = torch.nn.BCEWithLogitsLoss().to(device)
pred_real = discriminator(imgs_hr).detach()
pred_fake = discriminator(gen_hr)
loss_GAN = criterion_GAN(pred_fake - pred_real.mean(0, keepdim=True), valid)원문 코드에서 RaGAN 부분만 발췌하여 가져온 것이다. 일반적인 GAN이었다면 loss가 Criterion_GAN(pred_fake, valid)와 같았겠지만 RaGAN 구조를 사용하기 위해 실제 이미지를 Discriminator에 통과시켜서 평균을 구해 빼주고 있다. 이 loss은 Discriminator를 업데이트할 때도 사용되고, 위 코드처럼 Generator의 GAN loss로도 사용된다.
VGG loss
ESRGAN은 활성화 함수를 통과하기 전의 피쳐맵 값을 이용해서 VGG loss를 구한다. 이전의 SRGAN은 활성화 함수를 통과한 후의 피쳐맵을 이용했는데, 이러면 피쳐맵이 sparse 해진다는 단점이 있다. 그 결과로 업데이트가 제대로 이루어지지 않는다. 활성화 함수를 통과한 피쳐맵과 통과하기 전의 피쳐맵의 차이는 다음과 같다.
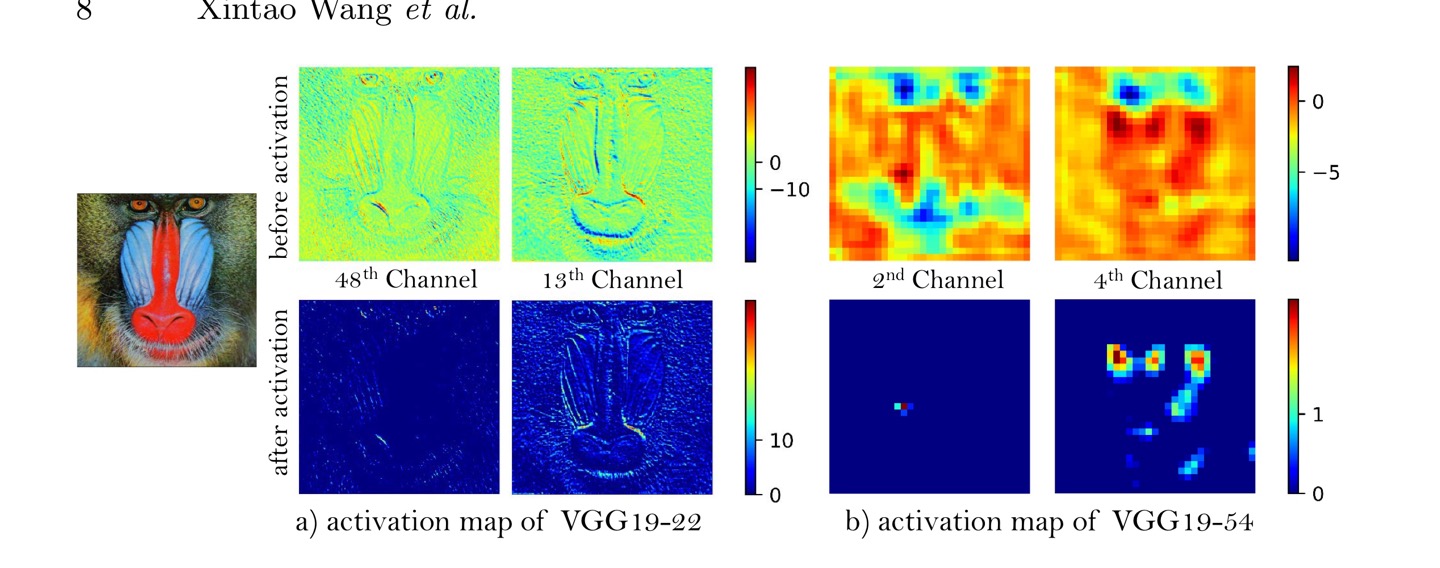
이 사진에서 윗쪽은 활성화 함수를 통과하기 전, 아래쪽은 활성화 함수를 통과한 후의 피쳐맵인데 한 눈에 봐도 활성화 함수를 통과하고 난 피쳐맵은 비활성화된 피쳐들이 많다. 이런 현상은 더 깊은 네트워크의 피쳐맵일 수록 심해진다. 위 사진에서 왼쪽과 오른쪽의 차이다. 오른쪽 아래를 보면 거의 모든 피쳐들이 비활성화되어 색이 보이는 피쳐가 많지않다. ESRGAN은 활성화 함수를 통과하기 전의 피쳐맵을 사용하여 이런 문제점을 해결하고자 했다.
Network Interpolation
기본적으로 GAN은 학습이 불안정하기 때문에 super resolution의 결과물에도 noise가 끼어 있을 수도 있다. 반면 이전의 PSNR 최적화 방식으로 학습된 네트워크의 경우 MSE의 영향으로 noise가 없이 부드러운 모습이지만 디테일은 떨어지는데, Network Interpolation은 이 두 딥러닝 네트워크의 weight를 합쳐 서로의 장점을 취하겠다는 것이다.
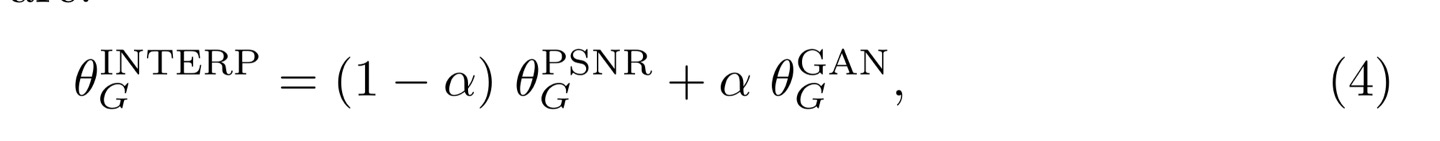
Network Interpolation은 위와 같이, 패러미터 alpha에 따라 PSNR로 학습한 네트워크와 GAN으로 학습한 네트워크의 패러미터들을 합성하는 것이다. 두 네트워크의 결과물의 값을 합성하는 것과 generator loss의 패러미터를 조절하는 것보다 network interpolation이 더 효과적으로 노이즈를 제거해줬다고 한다.
학습
최종적으로 Generator와 Discriminator의 학습과정은 다음과 같다. 우선 PSNR 최적화 방식으로 Generator를 먼저 학습시킨다. 이는 네트워크가 local optima에 빠지는 것을 방지하고 Discriminator가 완전 랜덤한 이미지를 받지 않도록 해준다. 그 후 Generator와 Discriminator을 수렴할 때까지 번갈아 학습시킨다. 모델 학습의 최종적인 코드는 다음과 같다.
enerator = GeneratorRRDB(opt.channels, filters=64, num_res_blocks=opt.residual_blocks).to(device)
discriminator = Discriminator(input_shape=(opt.channels, *hr_shape)).to(device)
feature_extractor = FeatureExtractor().to(device)
# Set feature extractor to inference mode
feature_extractor.eval()
# Losses
criterion_GAN = torch.nn.BCEWithLogitsLoss().to(device)
criterion_content = torch.nn.L1Loss().to(device)
criterion_pixel = torch.nn.L1Loss().to(device)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.Tensor
# ----------
# Training
# ----------
for epoch in range(opt.epoch, opt.n_epochs):
for i, imgs in enumerate(dataloader):
batches_done = epoch * len(dataloader) + i
# Configure model input
imgs_lr = Variable(imgs["lr"].type(Tensor))
imgs_hr = Variable(imgs["hr"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((imgs_lr.size(0), *discriminator.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((imgs_lr.size(0), *discriminator.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# Generate a high resolution image from low resolution input
gen_hr = generator(imgs_lr)
# Measure pixel-wise loss against ground truth
loss_pixel = criterion_pixel(gen_hr, imgs_hr)
if batches_done < opt.warmup_batches:
# 처음엔 PSNR로만 학습
loss_pixel.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [G pixel: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), loss_pixel.item())
)
continue
# Extract validity predictions from discriminator
pred_real = discriminator(imgs_hr).detach()
pred_fake = discriminator(gen_hr)
# Adversarial loss (relativistic average GAN)
loss_GAN = criterion_GAN(pred_fake - pred_real.mean(0, keepdim=True), valid)
# Content loss
gen_features = feature_extractor(gen_hr)
real_features = feature_extractor(imgs_hr).detach()
loss_content = criterion_content(gen_features, real_features)
# 세 loss를 패러미터를 이용해 합침
loss_G = loss_content + opt.lambda_adv * loss_GAN + opt.lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
pred_real = discriminator(imgs_hr)
pred_fake = discriminator(gen_hr.detach())
# Adversarial loss for real and fake images (relativistic average GAN)
loss_real = criterion_GAN(pred_real - pred_fake.mean(0, keepdim=True), valid)
loss_fake = criterion_GAN(pred_fake - pred_real.mean(0, keepdim=True), fake)
# Total loss
loss_D = (loss_real + loss_fake) / 2
loss_D.backward()
optimizer_D.step()원본 코드에서 모델 학습 부분만 발췌했다. 코드를 보면 warmup_batches가 되기 전까지는 L1loss로만 학습하고 그 후에 Generator와 Discriminator를 같이 학습하는 모습을 볼 수 있다. Generator의 loss는 GAN loss(Adversarial loss - RaGAN), Content loss(VGG loss), Pixel loss(L1 loss)가 패러미터를 이용해 조합되어 만들어진다.
결과
이 논문은 논문에서 제시한 개선점들을 하나씩 제거해가며 결과물의 차이를 보면서, 개선점들이 유의미했는지 증명하려 했다. 그 결과 개선점들이 모두 이미지의 디테일을 올리는 데 도움을 주고 있다는 것을 알 수 있었다. 또한 RRDB 구조를 사용하고 배치 정규화를 없앰으로써 모델은 더 깊으면서 학습은 쉽게 만들 수 있었다.
또한 network interpolation은 0에서 1 사이의 0.2 간격으로 패러미터를 주어 실험되었는데, 그 결과 network interpolation이 이미지의 부드러운 정도와 이미지 디테일 퀄리티 사이의 밸런스를 컨트롤 할 수 있었다
'Data Science' 카테고리의 다른 글
| [ML] 의사결정나무(Decision Tree) 뿌시기 (0) | 2022.05.21 |
|---|---|
| 누락값(Missing value)를 다루는 방법들 (0) | 2022.05.09 |
| [논문 리뷰] Attention is all you Need (transformer) (0) | 2022.03.04 |
| [논문 리뷰] SRGAN (0) | 2022.02.18 |
| 빈도주의 vs 베이지안 (0) | 2022.02.06 |